| Previous Lecture | Lecture 08 | Next Lecture |
Lecture 08, Wed 04/14
Wed Lecture: testing aspect of team01, mocking/stubbing in Java (Mockito), code reviews and PRs
Today we’ll look at the testing aspect of the project https://ucsb-cs156.github.io/s21/lab/team01/
We’ll discuss the goal with of unit testing of isolating the unit under test so that we test only the code inside that unit (i.e. a single method), by mocking and stubbing dependencies.
This relates to the concept of dependency injection, which we’ll also discuss.
Then, we’ll discuss three practices that you’ll follow throughout the quarter:
- Standup Meeting
- Pull Requests
- Code Reviews
Finally, we’ll put you in your breakout rooms so that you can try out these practices.
Dependency Injection
For testing purposes, you want dependencies to be loose rather than strict.
Example of EarthquakesController depending on EarthquakeQueryService:
- Suppose the correctness of module A depends on the correctness of module B
- Specific example: The
EarthquakesControllerdepends on theEarthquakeQueryServicedoing it’s job properly - For testing just the code in the
EarthquakesController, you want to temporarily set up a situation where the specific features of theEarthquakeQueryServicethat theEarthquakesControllerdepends on are mocked. - That is, you hard code an alternative implementation of the
EarthquakeQueryServicethat knows just how to take a specific input, and provide a specific return value from theEarthquakeQueryService. - That allows you to test the service in isolation.
Links to code:
Example of EarthquakeQueryService depending on an external API (the one from the US Geological Survey):
- Suppose the correctness of module A depends on the correctness of an external service, one that isn’t even provided by code that we wrote!
- Specific example: The
EarthquakeQueryServicedepends on the API provided by the US Geological Survey - The code for your
EarthquakeQueryServicecould be 100% correct, but if the USGS web server is down, theEarthquakeQueryServicewon’t perform correctly. - Plus, the data returned by the
EarthquakeQueryServicecan change over time; even for past earthquakes! From time to time, the USGS gets new data readings and updates data for past earthquakes. So there is no way to be sure when we write a test what the “correct” answer should be. How can we test such a service? - Solution: for testing just the code in the
EarthquakeQueryService, you want to temporarily set up a situation where the interaction with the external API is mocked. Instead of doing a real call to the USGS server, we set up a “fake” server that is expecting a certain URL to be requested, and will return a certain fake value. - We then can check that when we pass in particular parameters, the service does indeed call out to the specific URL, and that the value returned by the URL is processed in the way we expect and returned from the service.
Links to code:
Pros/Cons of Mocking and Stubbing
Mocking and Stubbing is a widely used practice in the software industry, and definitely is an important thing to know about.
We also acknowledge that it has its limitations, and its critics:
Some pros:
- Good isolation of tests; you can test each component by itself
- In order to be able to test in this way, you do need to keep each module small, which promotes some good software engineering practices:
- Single Responsibility Principle: each module should have “just one job” (sometimes expressed as “one reason to change”).
- Modules should depend on one other “loosely” through well defined APIs, rather than depending on internal details.
Some cons:
- Tests written in this way can be brittle meaning that they break frequently when changes to the code are made.
- This is because they often depend on internal details of the code; ideally tests should depend on external behavior only, and not on internal implementation details.
- Some feel that this level of testing doesn’t sufficiently get at the big picture, i.e. “does the app really work”? They prefer integration tests that check the behavior of the app as a “black box”, i.e. test that only work through the RESTful API, or the user interface of the app.
This brings us to a concept call the testing pyramid. The following diagram is copied from the article The Practical Test Pyramid by Martin Fowler, which I encourage you to read if you are interested in this topic. The diagram itself is attributed to Mike Cohn.
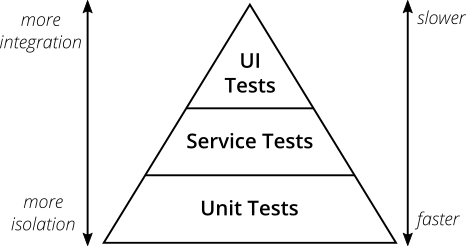
(This diagram uses the phrase “service tests” where many other sources use “integration tests”, but it’s the same concept. Unfortunately, terminology in CS and Software Engineering is not nearly as standardized as we might hope for.)
Martin Fowler discusses the pros/cons of various types of testing, and of the test pyramid concept itself, but arrives at two big-picture take aways that represent something like the mainstream consensus, though individual opinions will vary:
- Write tests with different granularity
- The more high-level you get the fewer tests you should have
Point 1 says that it’s useful to write:
- unit tests that isolate components
- integration tests that check whether components work together
- end-to-end (e2e) tests that actually interact with your application from start to finish, automating the exact steps a real user of your app would take (whether that user is a human being, or another computer program)
Point 2 says that as we move up this pyramid, there will likely be fewer tests
- lots of unit tests, ideally ones that cover all or most of your functionality
- some integration tests
- just a few e2e tests
The reasoning behind point 2 is that lower in the pyramid, the tests are:
- the lower you are in the pyramid, the faster the tests are to write, and the faster they run
- the higher you are in the pyramid, the more time consuming the tests are to write, and the slower they run
I would also acknowledge that:
- the lower you are in the pyramid, the less value there is to each individual test
- the higher you are in the pyramid, the more value there is to each individual test
Standup Meeting
One of the common practices when teams use the software design life-cycle methodologies known as Agile and/or Scrum is the Standup Meeting.
- For full-time teams, this is usually held near the start of the workday
- An important feature: timeboxed. Meaning, it should take no more than 5-10 minutes.
- If it takes longer, you are aren’t doing it right, or at the very least, you aren’t doing a “standup”.
- If the team needs to do something other than a “standup”, the team may make that choice, but be clear about it.
- The name “standup” comes from the fact that, traditionally, the meeting is done, for folks that are able to stand,
while physically standing, rather than sitting.
- The motivation is that if you are standing, you’ll be reminded that the meeting is supposed to be 5-10 minutes and no more.
- On zoom, folks may or may not adhere to this literally, but I do encourage it.
What happens in a standup is typically this: each team member, one-by-one, speaks and tells the team:
- What work have they done in support of the team’s goals since last standup
- What are they working on now
- Are their any blockers they need help with addressing?
This last point is important.
- The purpose of a standup is not supposed to be a “status update for management” (or in a course, a “status update for the course staff”
- The audience is the other team members
- The purpose is to clear away obstacles.
Let’s put this in the context of today’s class meeting. I highlighted the text in support of the team’s goals above.
The specific team goal that I want to highlight in today’s standup is
- completing the team01 assignment
So, each member may like to describe:
- where are they with their individual work on that assignment. There are 10 steps, labelled 2.0 through 2.9; you might mentioned which of those steps you are on (or if you haven’t started yet, say that; or if you have finished all of these steps say that.)
- what they plan to do next
- the most important part: any blockers they have
Blockers could be:
- not understanding what you are supposed to do
- being stuck on something
But they could also include things like:
- motivation
- time-management
As a team, I encourage you to support one another with both kinds. The team’s success depends on it.
Whatever the blockers are, during the standup:
- just identify
- If it can be solved in less than 60 seconds, fine–solve it immediately
- Example: “Oh, I ran into that problem too. Here’s the command you need to fix that”.
- Example: “Oh, I know the problem you mean. After standup, I’ll drop a link to a article that describes how to get around that problem.”
- But, if it is a 5 minutes discussion, then that doesn’t belong in standup
- Instead, identify it, in the slack chat as something you’ll do after standup.
A modififed standup for Zoom / Class (P04)
During the Zoom era, and so that the staff can help you practice with standups, I’d like to propose the following structure. This is also today’s particpation activity (P04).
- When you get to your breakout rooms, one person will share their screen, and point at the Slack channel for the team.
- Start a two minute timer (if you type
two minute timerinto Google, it will bring up one on the search results directly, or there are lots of fun countdown timers on YouTube as well.) - During the two minutes, each person types into the Slack channel their standup summary:
- What stage of team01 are you on? Mention the number (2.0 through 2.9), but also describe it in words.
- What are you planning to do next
- What blockers (if any) do you have (answer could be “none”)
- After the two minutes, go through and have each person unmute themselves and share their status update out loud. This may
seem redundant, but there’s a purpose:
- It’s an opportunity for the team to focus on each person’s sharing one at a time, and…
- … more importantly to respond to each person’s sharing.
- If there are blockers that can’t be dealt with immmediately, make a note to deal with them after standup.
- Once everyone has shared, standup, per se, is over. But now, deal with the blockers if any.
- This may be a longer discussion, and it might be one where the whole team doesn’t need to particpate.
- For example, it might be two team members going into a separate breakout room to discuss the solution to a problem.
A particular “blocker” is if the team members has made their pull request and is waiting for a code review, and for their PR to be merged. We’ll discuss that one next if time permits; if not, we’ll return to it on Monday.